Notes: RL Foundational Models
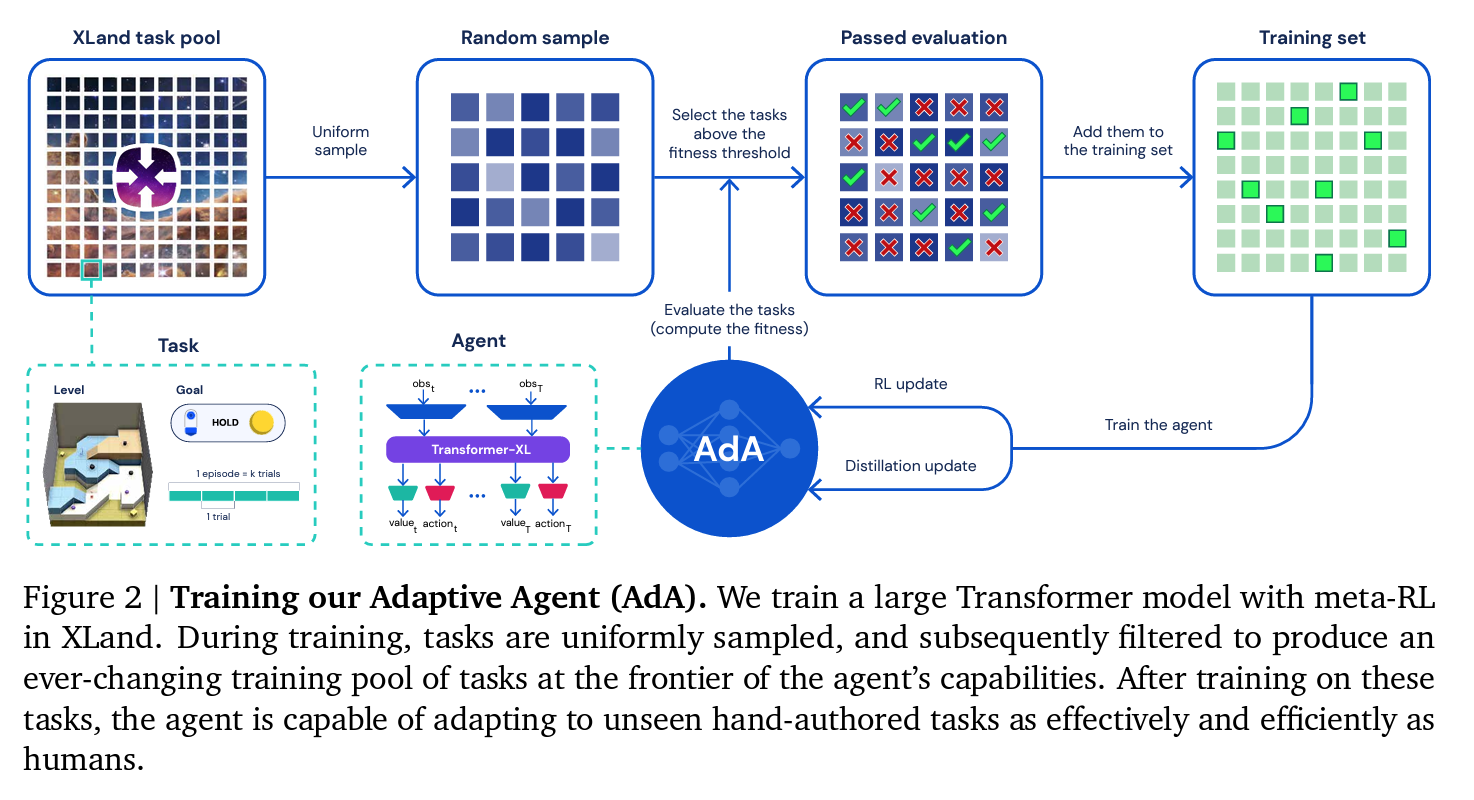
What the suite looks like:
 10^40 states
10^40 states
- performes about the same as muZero but without planning
- However because it doesn’t have a learned internal model, it’s not the most sample efficient.
Distillation
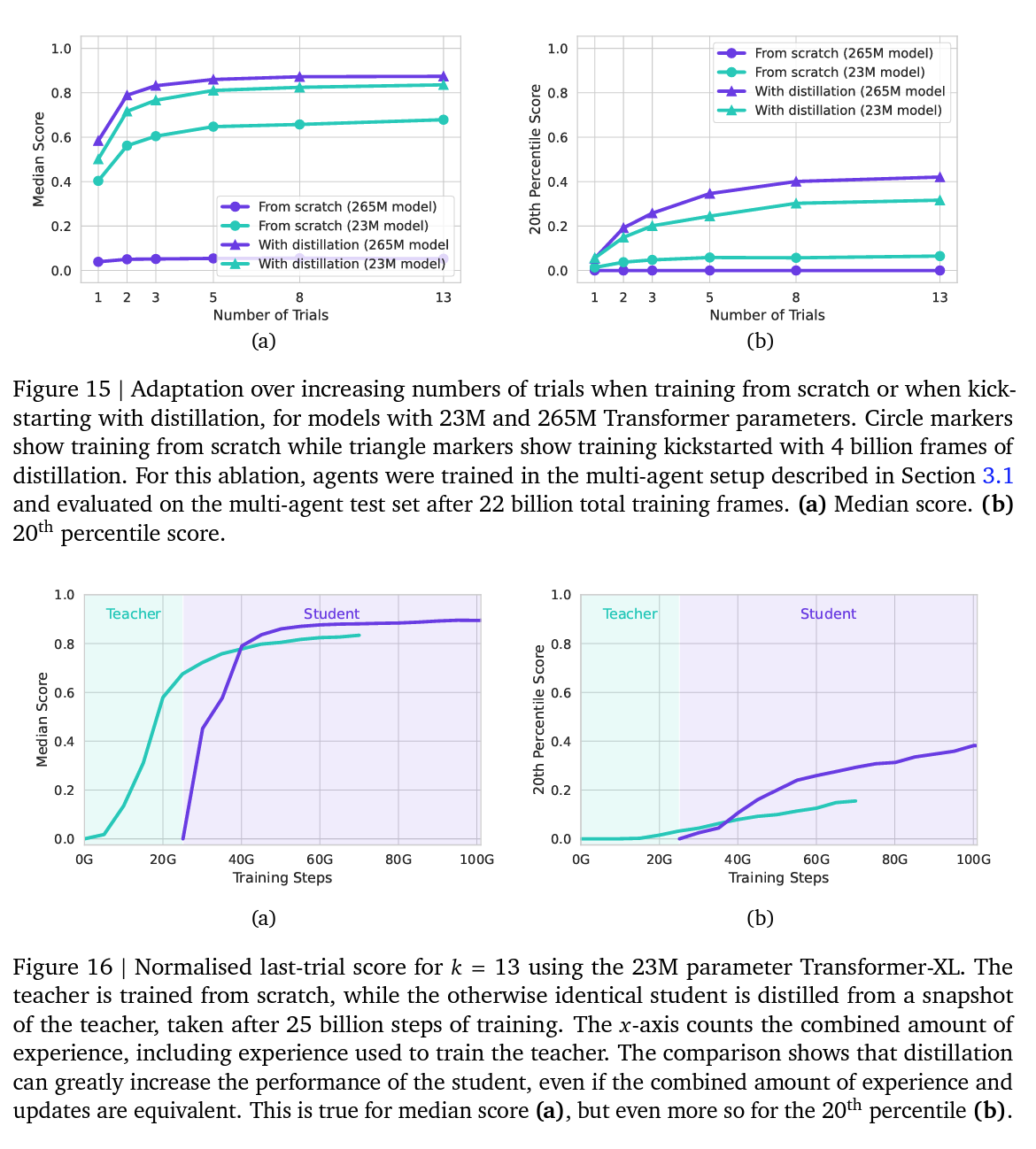
Note: distillation loss is used to train the large model faster.
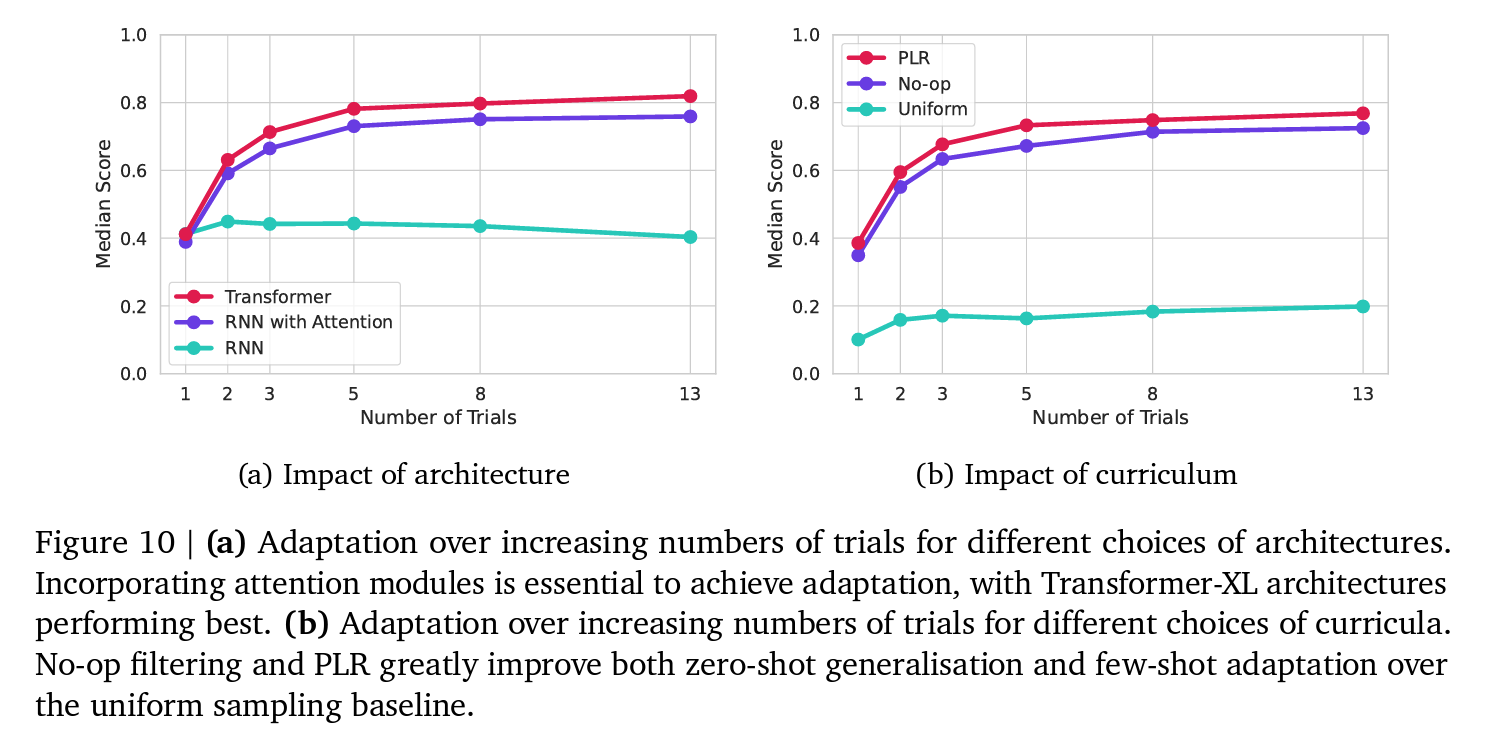
Auto-curriculum learning
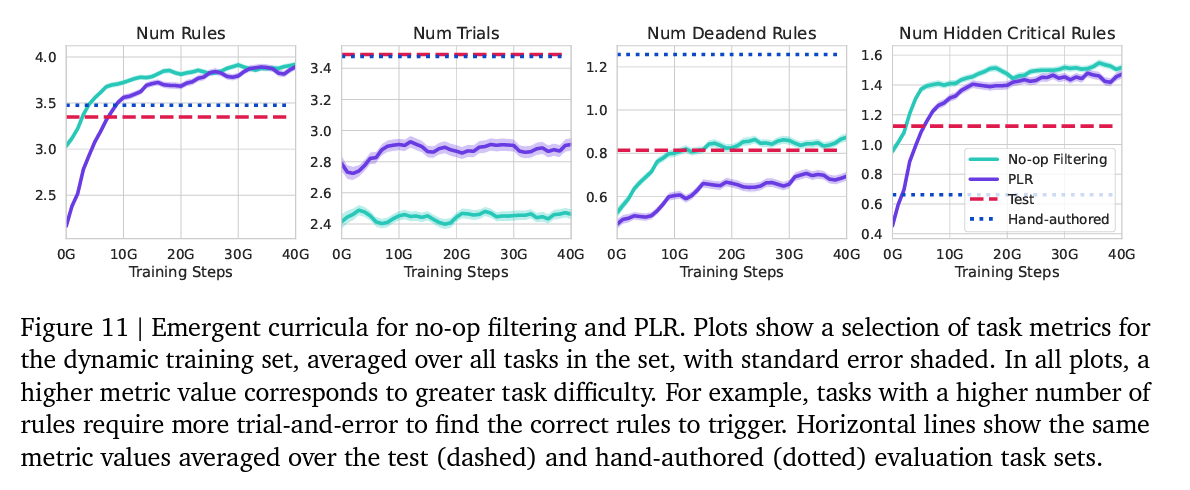
- No-op filtering
- Prioritized level replay
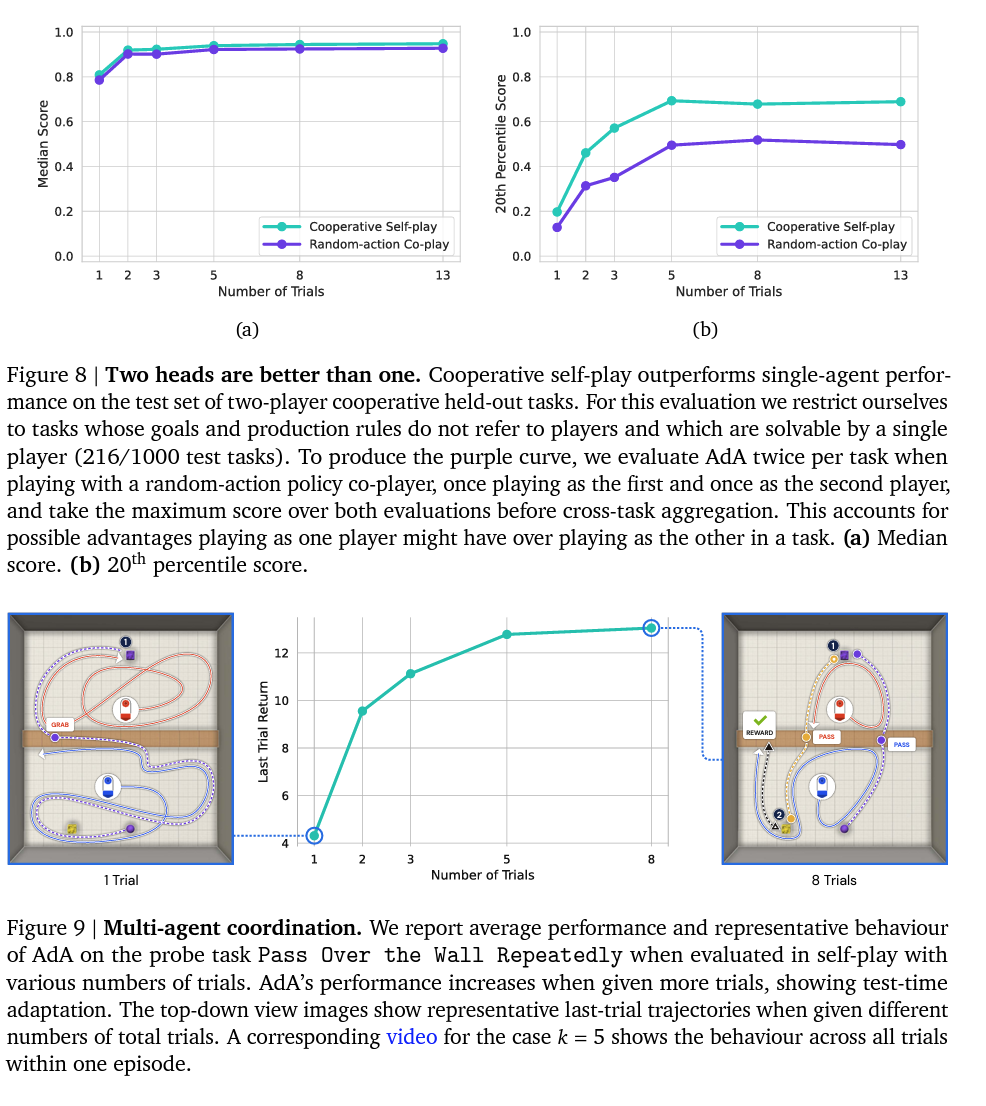
Multi-agent:
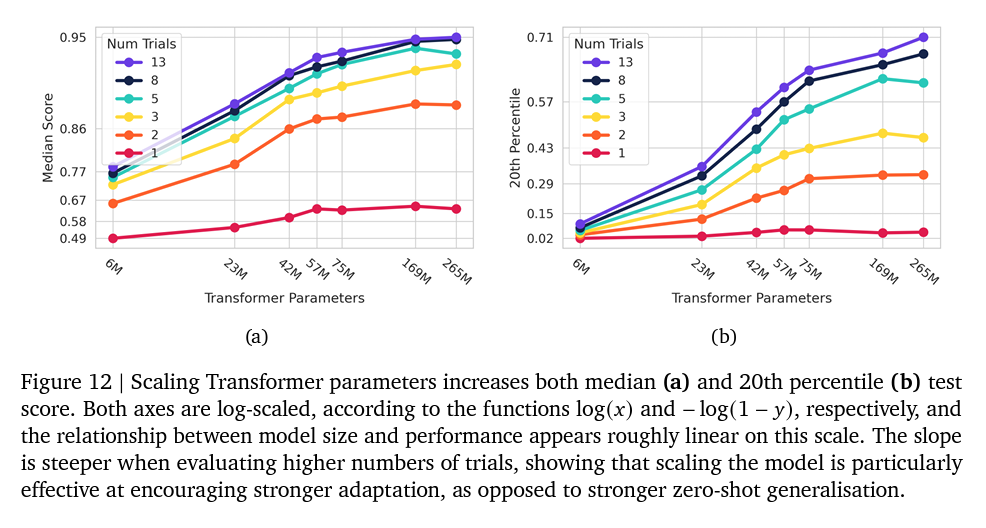
Scaling:
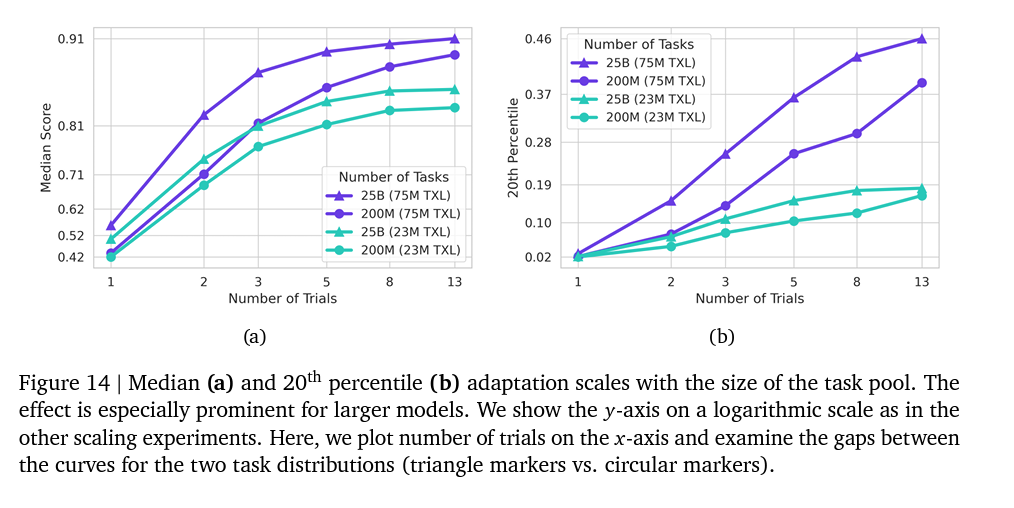
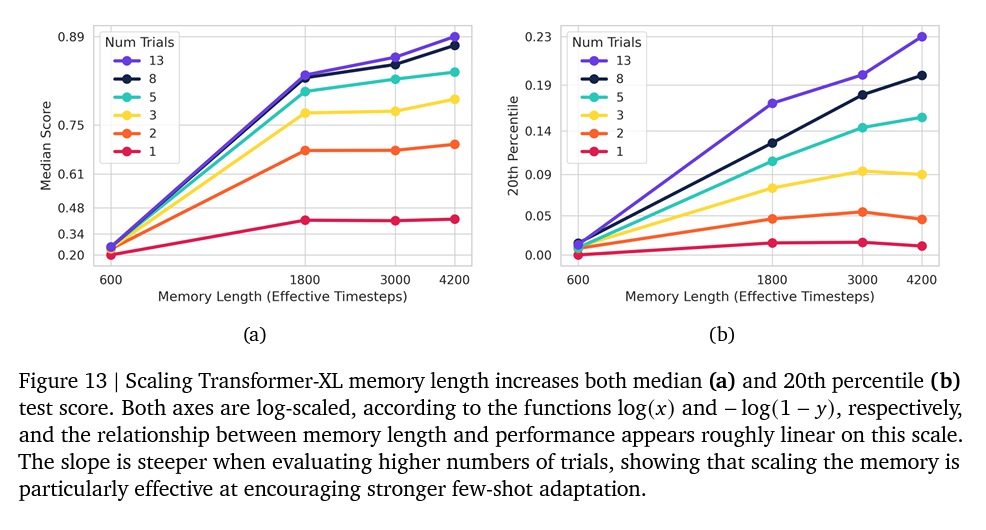 context window for 300 trial * 5 steps = 1500. However, a 1800 context size is still usefull.
context window for 300 trial * 5 steps = 1500. However, a 1800 context size is still usefull.