Notes: Code Generation Models
Evaluating LLM trained on Code
Why code
- good size corpus napkin math
- hierarchical structure
- automatically tested
- Errors/stacktraces are just language
- Eval tool edge
- A lot of ‘context information’ - documentation, commits, diffs, PR, etc…
- Complimentary skills for most other downstream tasks.
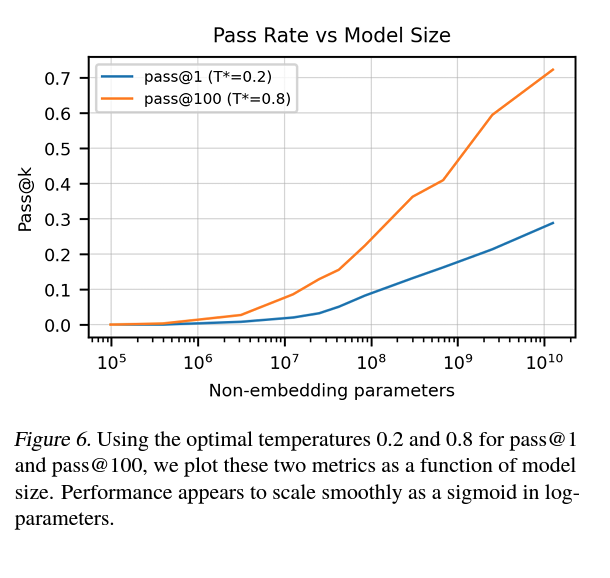
Downstream evaluation
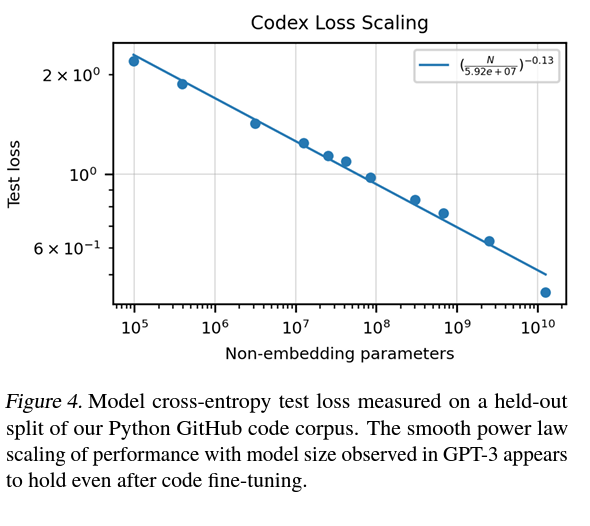
Language modeling vs. code generation

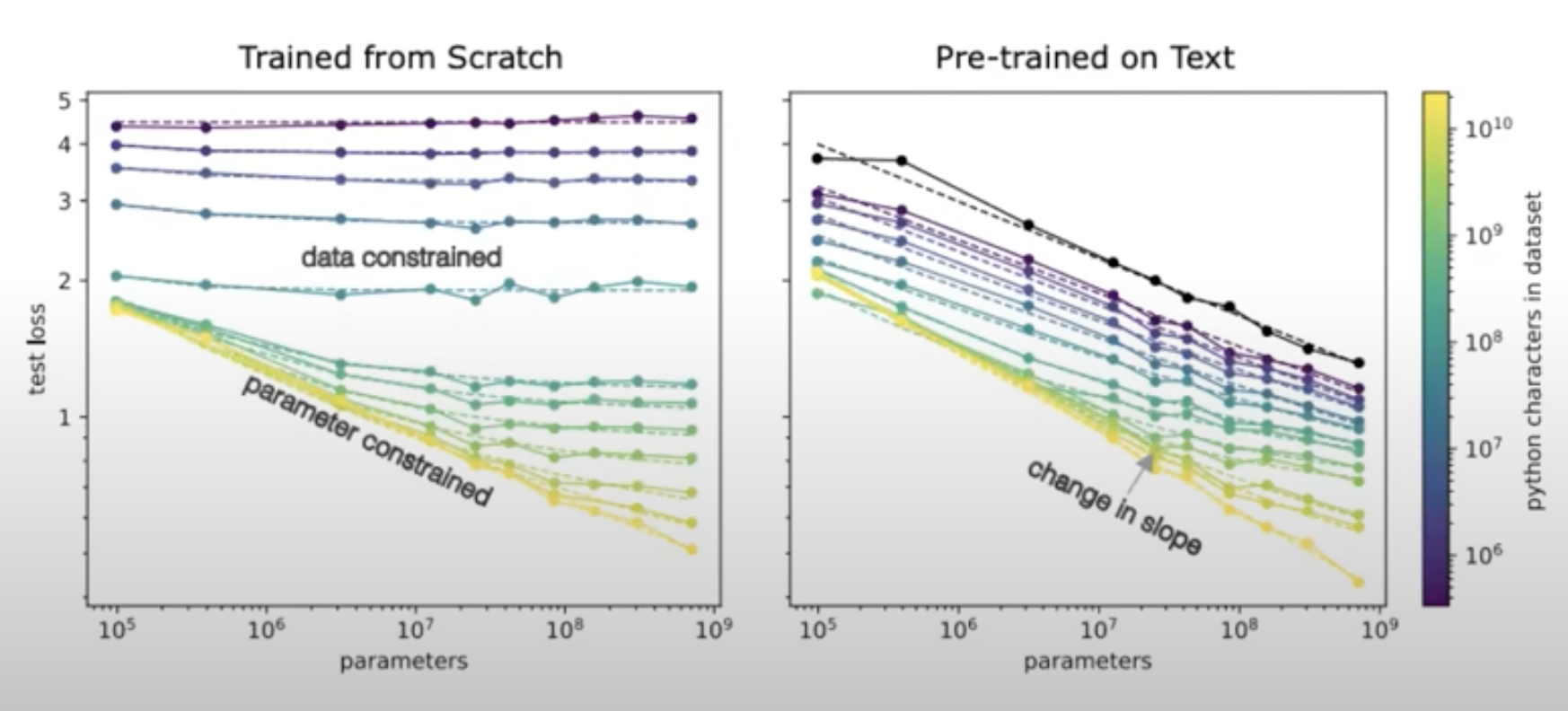
Fine-tuning: “Effective data transfer”
Data Size:
- GPT-3 trained on 300B tokens, ~200B words.
- Dataset grows slowly with model size.
- 1T words enough for a 10x larger model?
- Common crawl = 10^14 words
- Library of congress = 10^7 * 10^5 = 10^12 words (overestimate)
- Python on Github = 50B tokens.
- Just scaling up model size will run into data limitations soon. However what about transfer?
Generate more samples
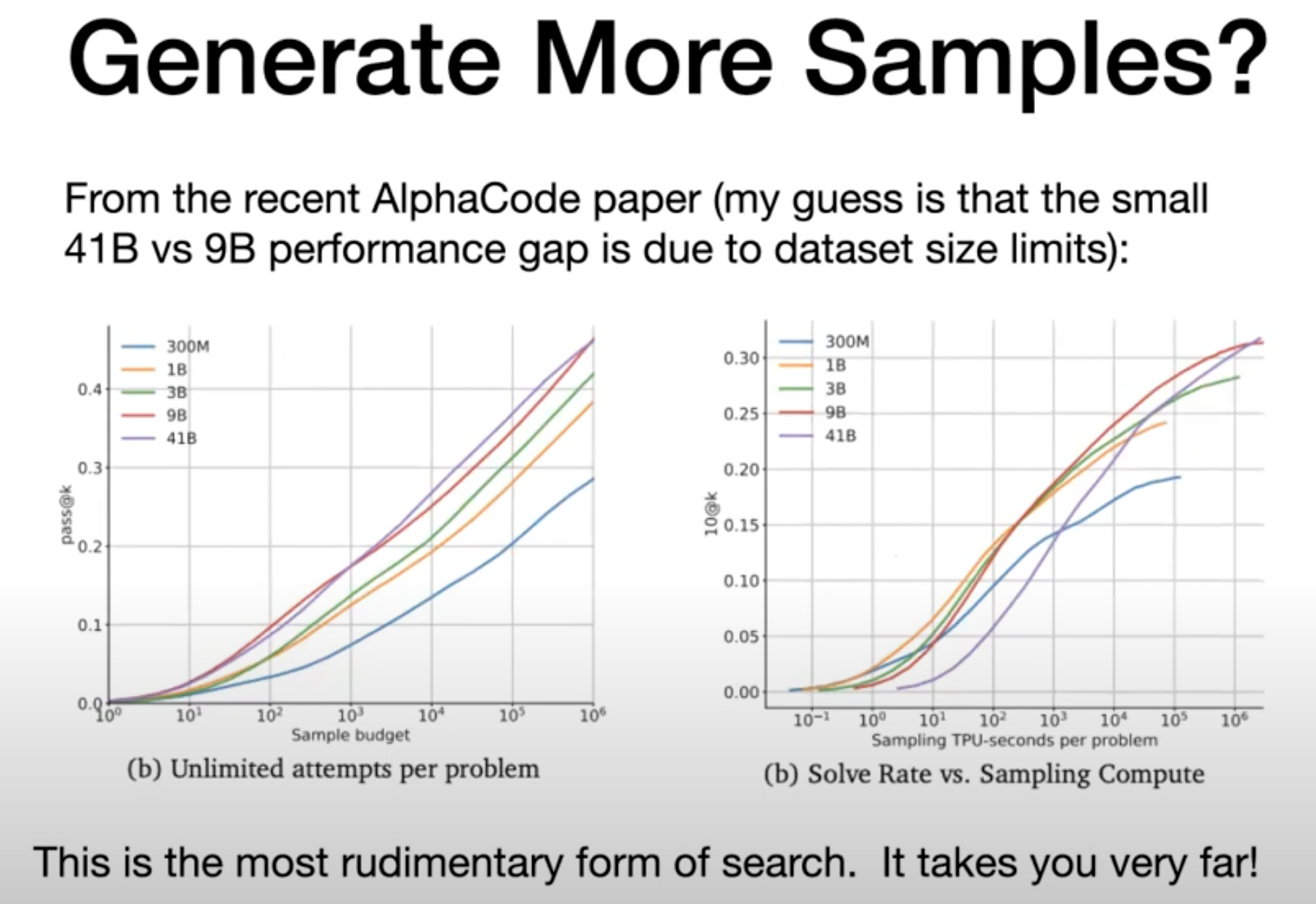
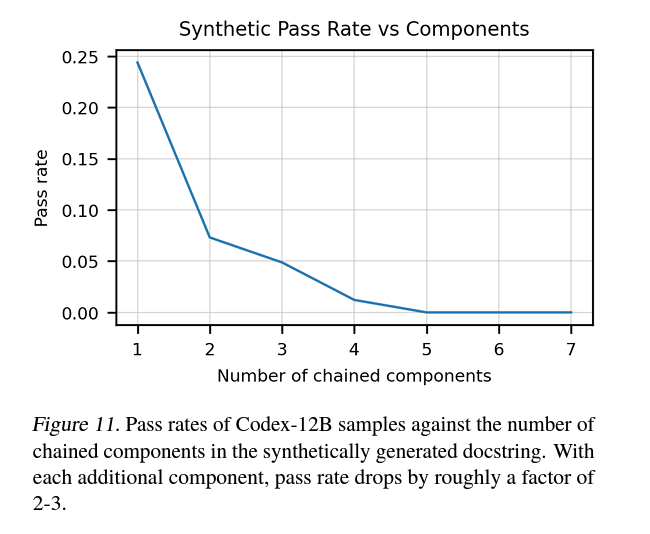
Longer programs
Discriminators

- Binary discriminators for “is this code correct?” (is this code valid is easy)
- These don’t do much better than log-probs of code-trained LM
- Naive RL -> value function won’t learn much. Plausibily suggest that naive RL for function synthesis is a weak problem formulation.
- One would hope to do much better by using more information (ex. stack traces, human-feedback etc…).
- “Generate many samples” is the most naive form of search, and search is the most naive form of RL…..in the presense of a good automatic evalaution, this may work.
Ranking
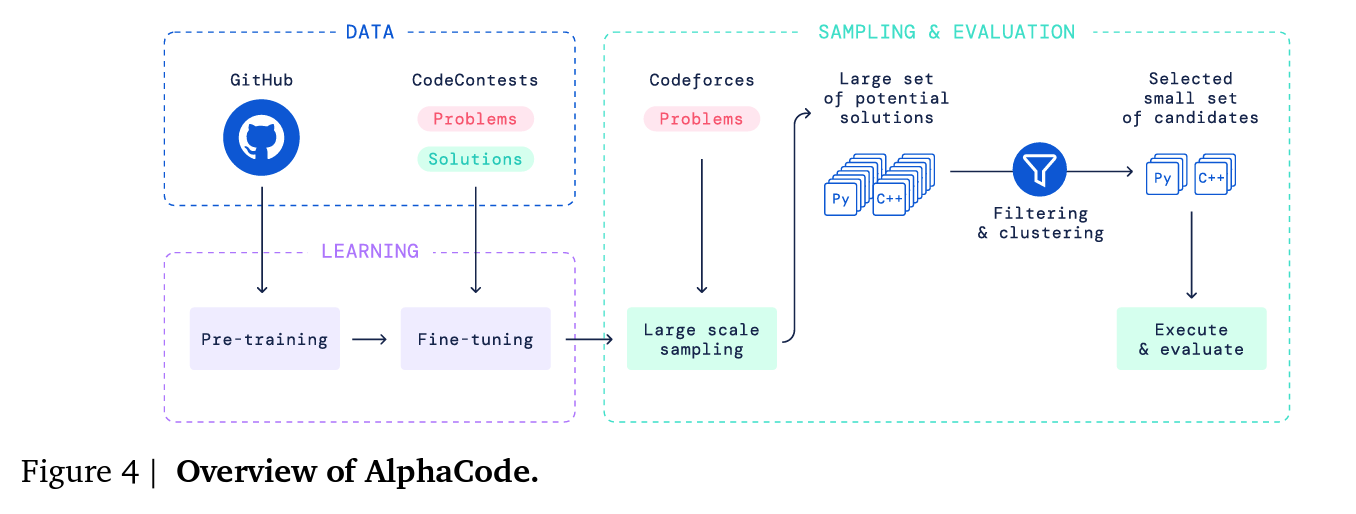
Approach:
- Pre-train LLM on Github with standard lanugage modeling objective.
- Fine-tune on code generation task (competitive programming).
- Generate a very large number of samples for each problem.
- Filter the samples to obtain a small set of high-quality solutions (~10).
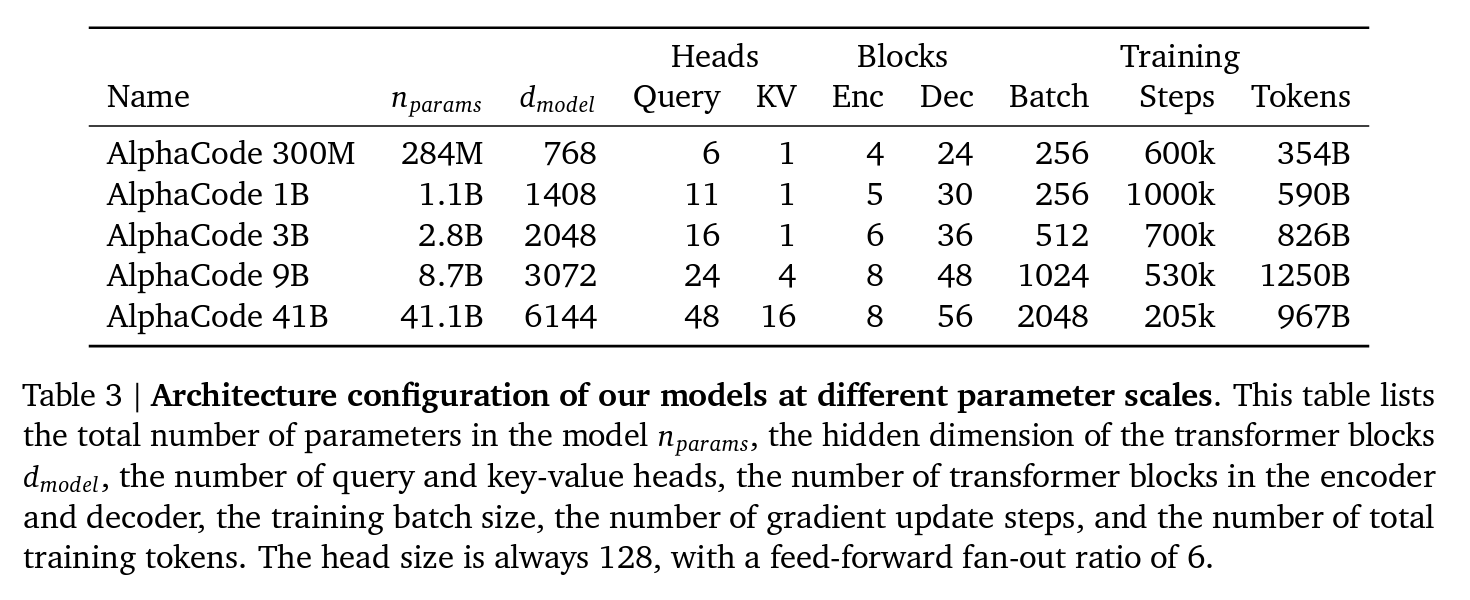
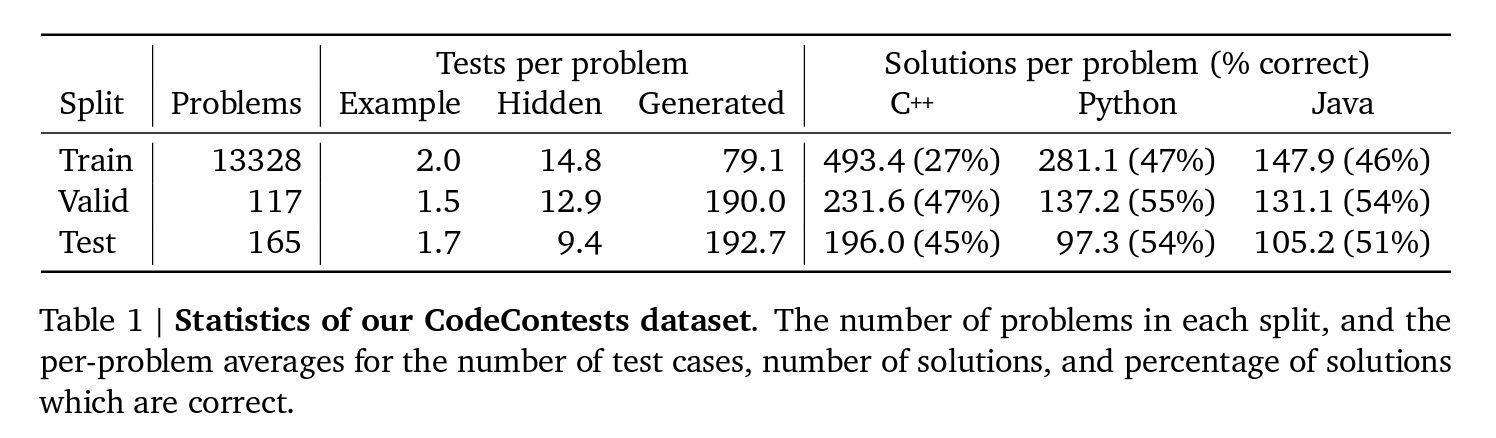
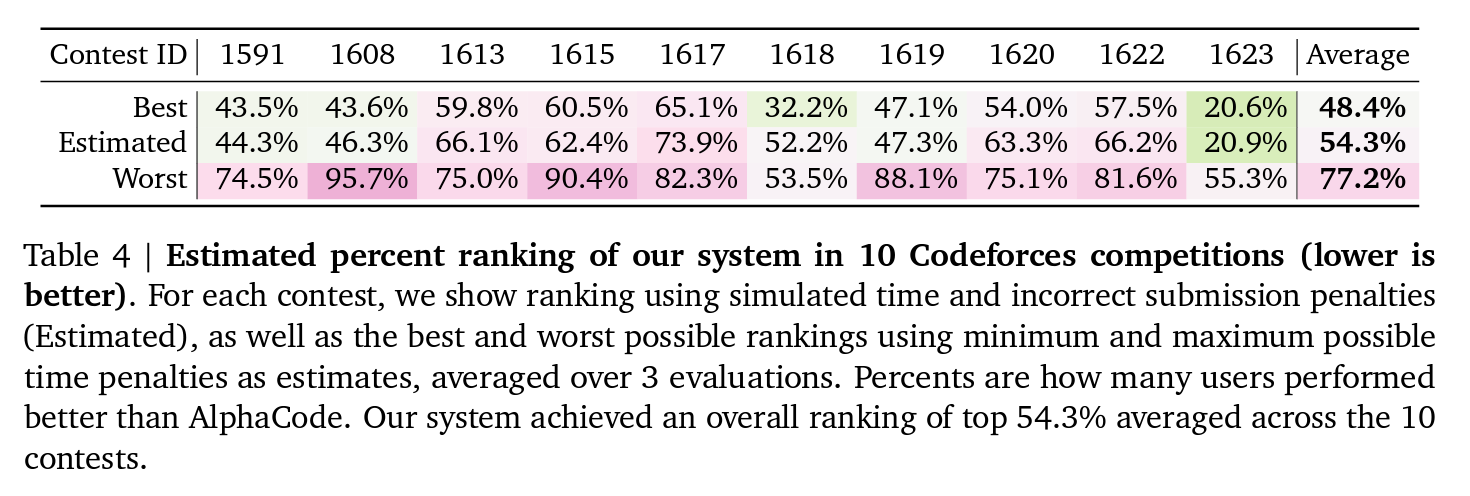
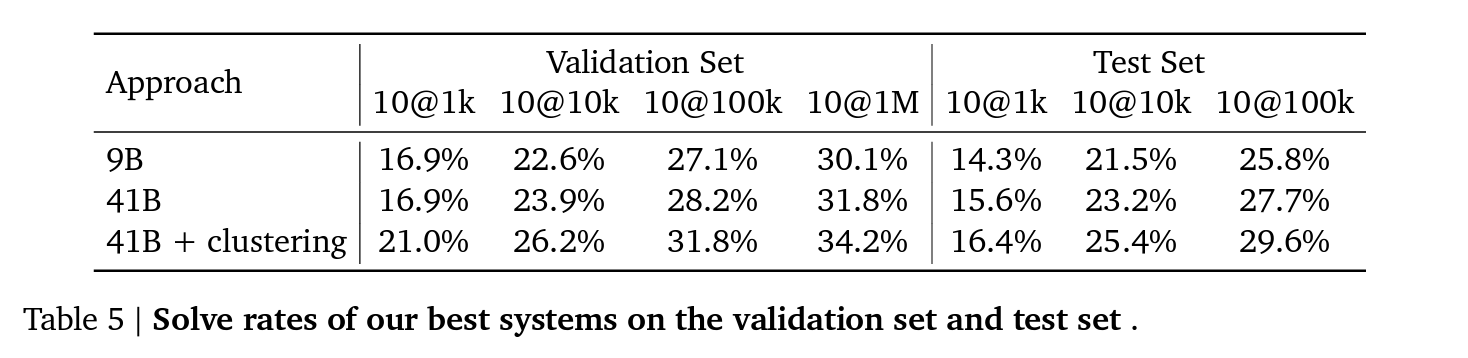
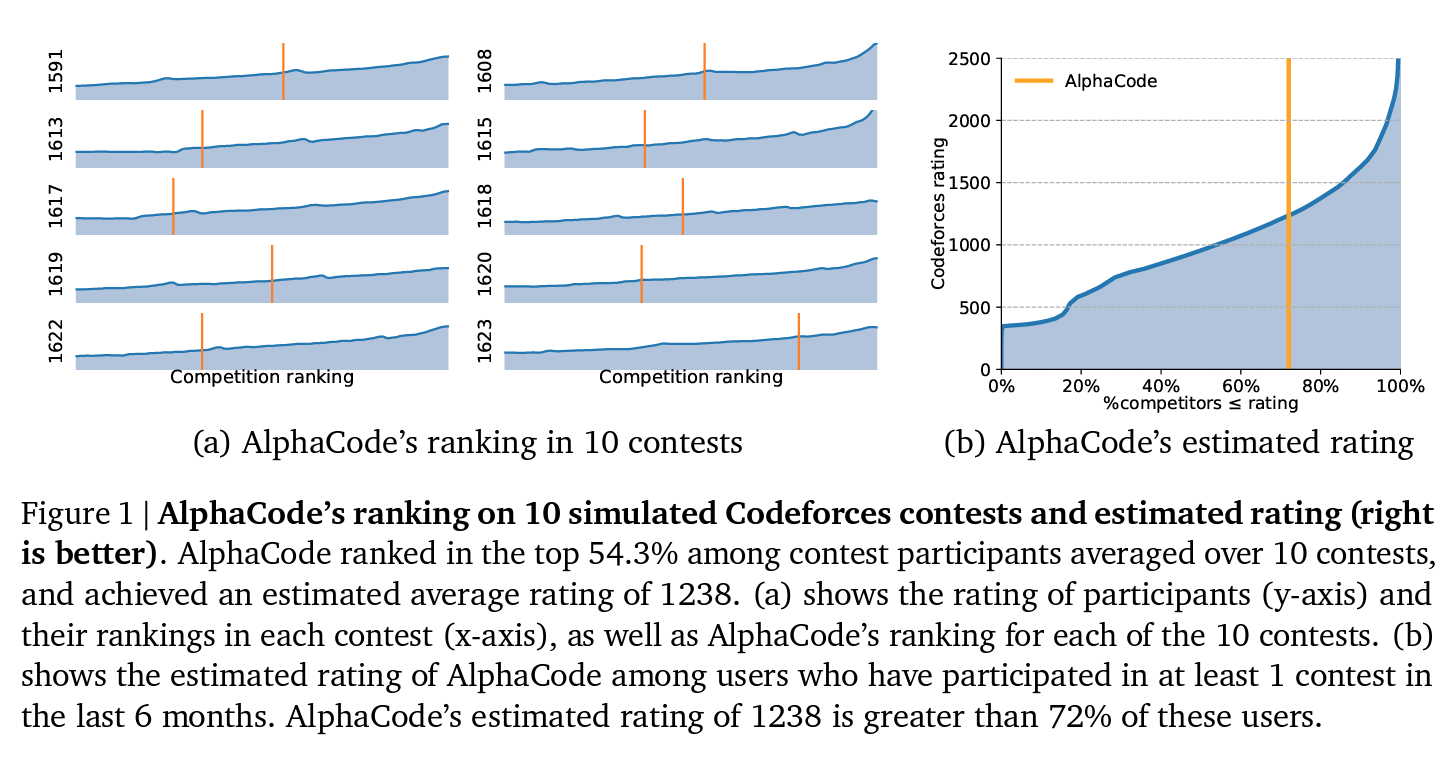
Progress by method:
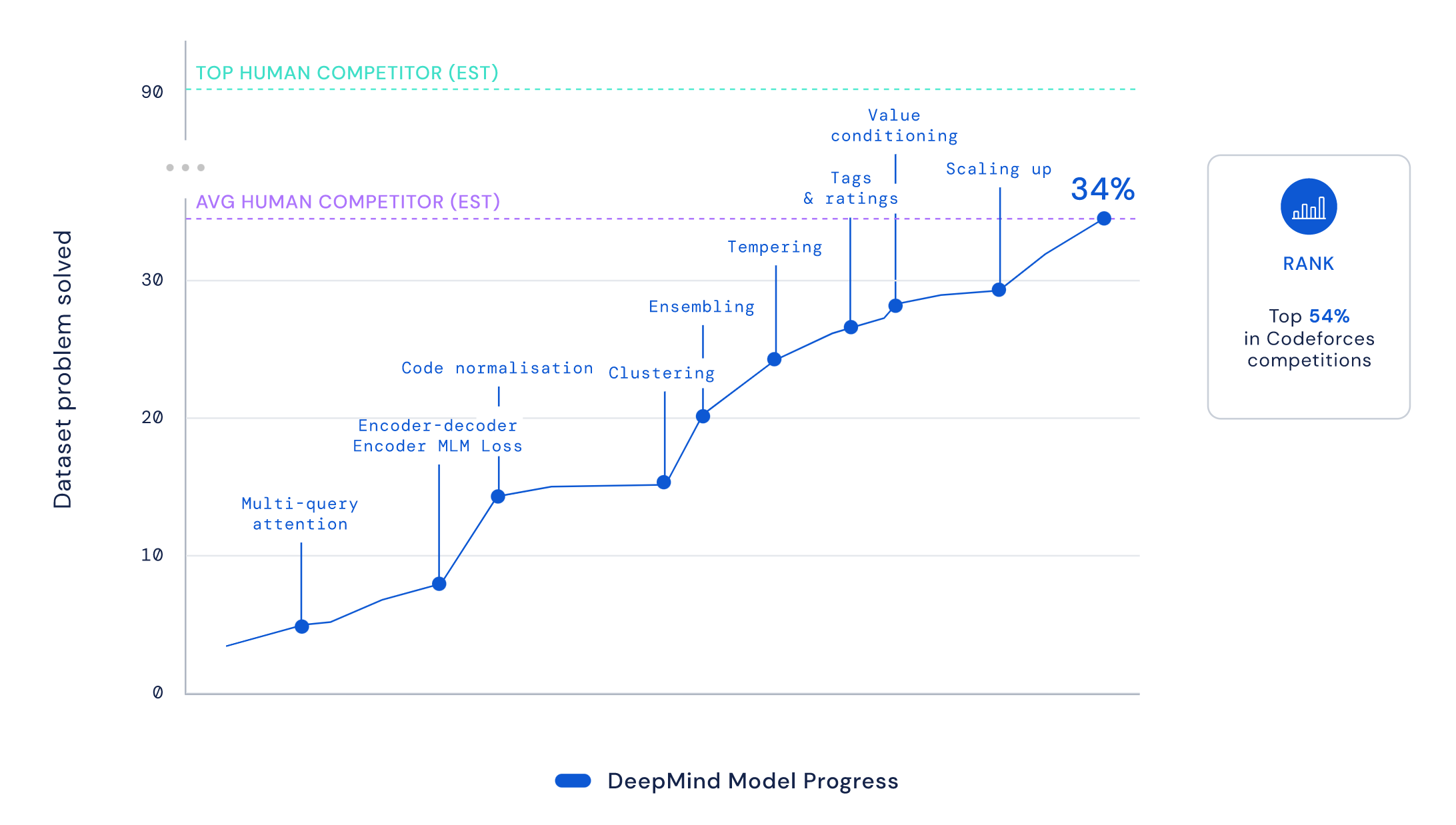
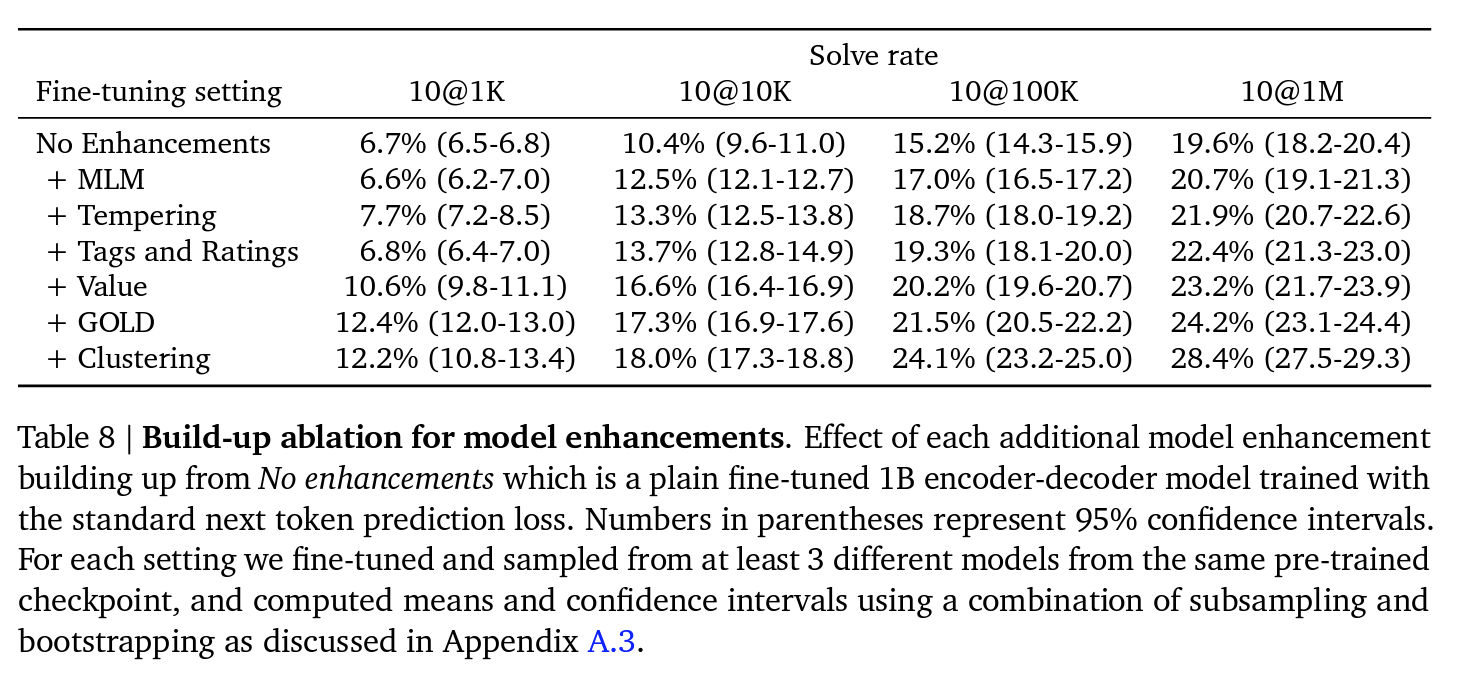
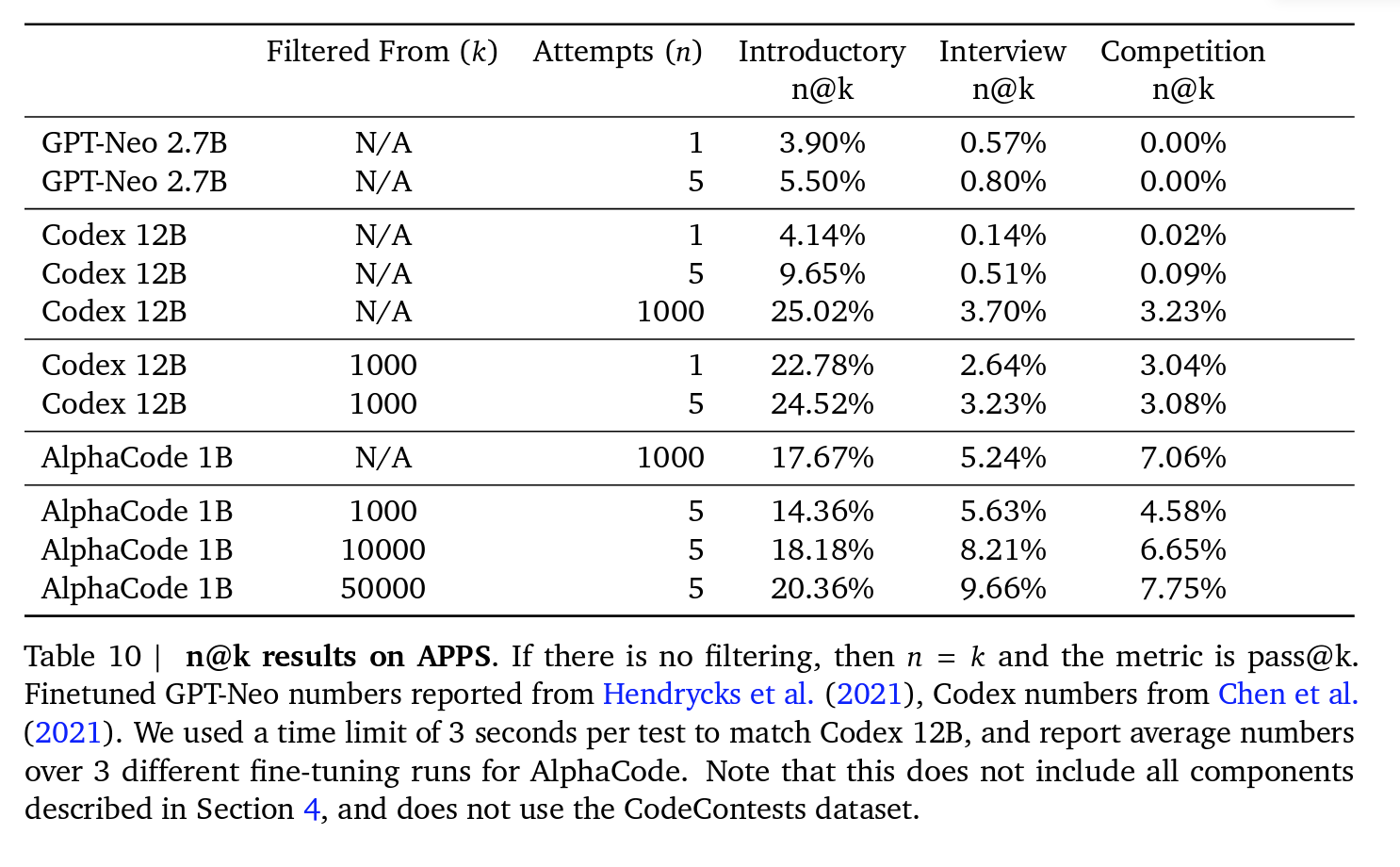
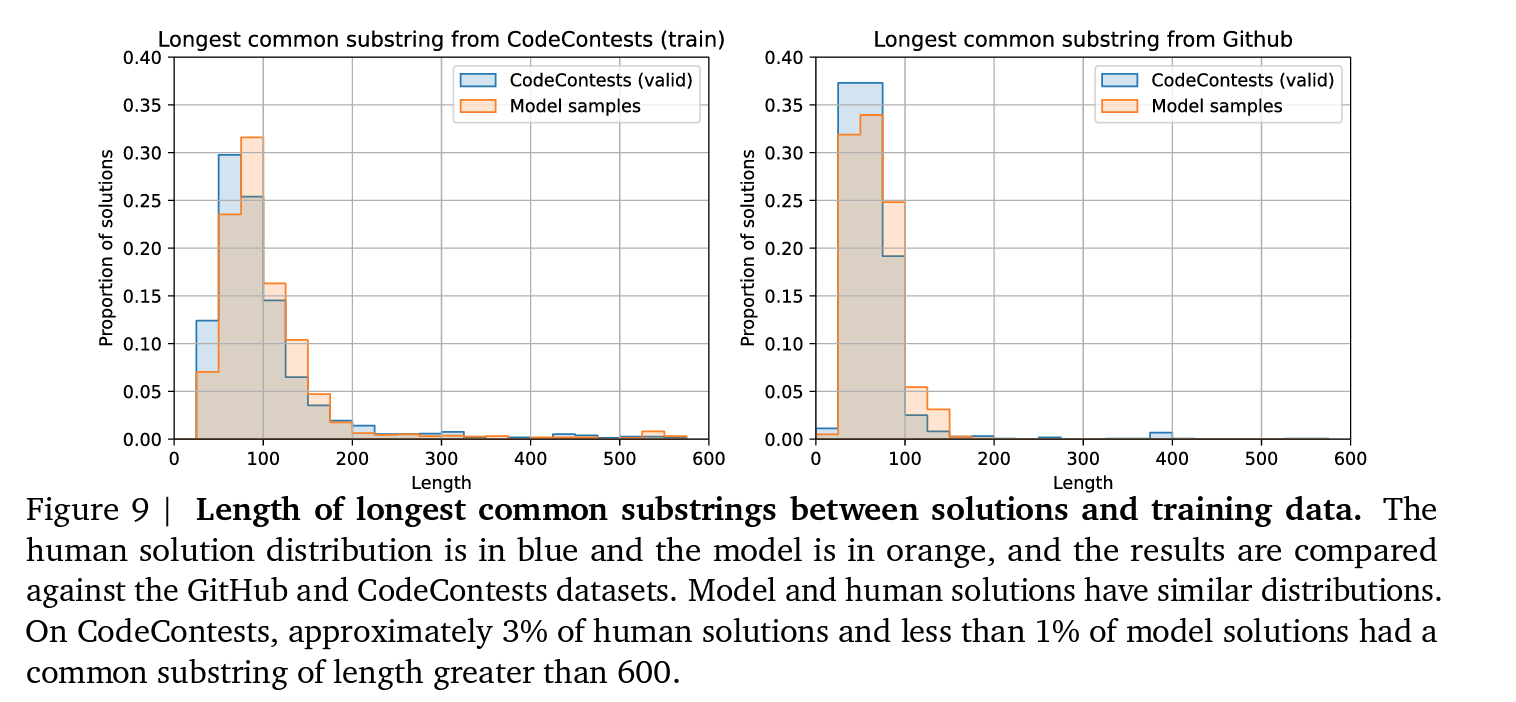
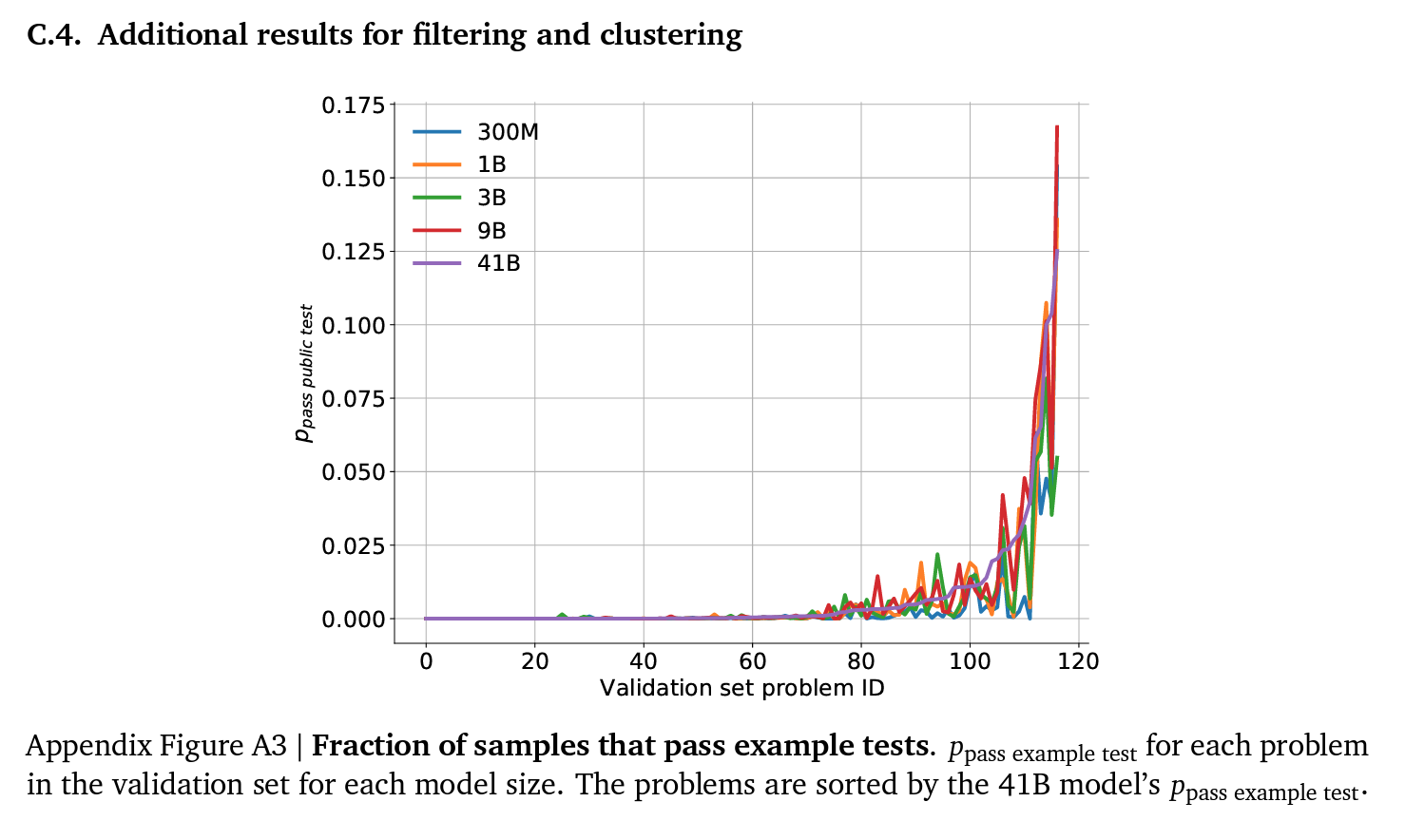
Filtering and clustering