Background
- Multi-task learning (MTL) is a training paradigm in which machine learning models are trained with data from multiple tasks simultaneously. The model does this by learning a shared representation to learn common ideas between collection of related tasks. In addition to a lot of active research in the field, many industrial application have seen success.
- Benefits include:
- Negative transfer (or destructive transfer) are drawbacks - Improving the model performance on one task will lower the performance on other tasks. Many architectures are designed with specific features to decrease negative transfer. This include adding task specific model features and attention mechanisms. However, figuring out the division of information between tasks is hard - we would like to allow the flow of information between tasks that minimizes the negative transfer.
- MTL methods have been broken down in the following groups:
- Hard parameter transfer (also known as
multi-task architecture): Sharing model weights between tasks. Here each weight is trained to jointly minimize loss function(s) on all task at the same time.
- Soft parameter transfer (also known as
optimization techniques): Different tasks have individual task-specific models with separate weights. However, the distance between the model parameters is added to a joint objective function.
- Task relationship learning.
Architectures
- Too much sharring will lead to negative transfer, while too little sharring does’t allow the model to effectively leverage the information from other tasks and generalize.
- Three types of architectures:
- Architectures for a particular task domain (ex. vision, speech, music).
- Multi-modal architectures.
- Learned architectures - fixed between steps of architecture learning, so that the same computation is performed for each input from the same task.
- conditional architectures - architectures used for a given piece of data is dependent on the data itself.
Architectures for Computer Vision
- Shared Trunks: A global features extractor made of convolutional layers (ex. VGG, ResNet) followed by an output branch for each task.
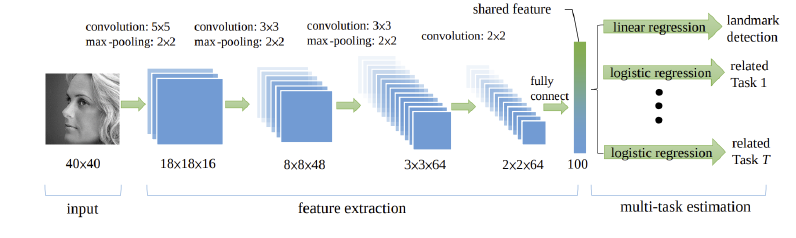 Zhang 2014 - A typical shared trunk architecuture
Zhang 2014 - A typical shared trunk architecuture
- (Zhang et al., 2014; Dai et al., 2016; Zhao et al., 2018; Liu et al., 2019; Ma et al., 2018) propose architectures which are variations on the shared trunk idea. (Zhang et al., 2014), the earliest of these works, introduces
Tasks-Constrained Deep Convolutional Network (TCDCN). The authors propose to improve performance on a facial landmark detection task by jointly learning head pose estimation and facial attribute inference.
- (Dai et al., 2016) introduces
Multi-task Network Cascades (MNCs). The architecture of MNCs is similar to TCDCN, with an important difference: the output of each task-specific branch is appended to the input of the next task-specific branch, forming the “cascade” of information flow after which the method is named.
- (Zhao et al., 2018) introduces a modulation module in the form of a task-specific channel-wise linear projection of feature maps, and the authors design a convolutional architecture with these modules following convolutional layers in the latter half of the network. Interestingly, it is empirically shown that the inclusion of these task-specific projection modules decreases the chance that gradient update directions for different tasks point in opposite directions, implying that this architecture decreases the occurence of negative transfer.
- (Liu et al., 2019) proposes task-specific attention modules. Each attention module takes as input the features from some intermediate layer of the shared network concatenated with the output of the previous attention module, if one exists. Each module computes an attention map by passing its input through a Conv-BN-ReLU layer followed by a Conv-BN-Sigmoid layer. The attention map is then element-wise multiplied with features from a successive shared layer, and this product is the output of the attention module. This attention module allows the network to emphasize features in the network which are more important for the corresponding task, and downplay the effect of unimportant features.
- Multi-gate Mixture-of-Experts (Ma et al., 2018) is a recently proposed shared trunk model, with a twist: the network
contains multiple shared trunks, and each task-specific output head receives as input a linear combination of the outputs of each shared trunk. The weights of the linear combination are computed by a separate gating function, which performs a linear transformation on the network input to compute the linear combination weights. The gating function can either be shared between all tasks, so that each task-specific output head receives the same input, or task-specific, so that each output head receives a different mixture of the shared trunk outputs.
- Cross-talk: Instead of a single shared extractor, these architectures have a separate network for each task, with information flow between parallel layers in the task networks, referred to as cross-talk.
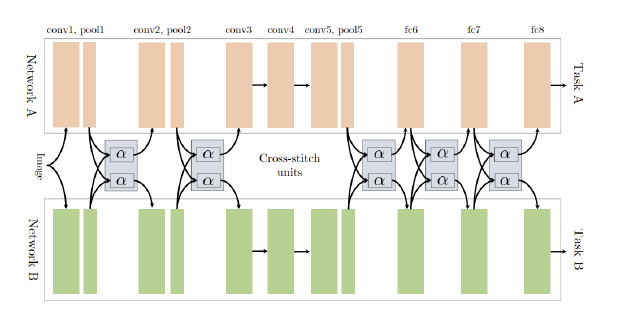 Cross talk architecture - Misra 2016
Cross talk architecture - Misra 2016
Architectures for Natural Language Processing
Architectures for Reinforcement Learning
Architectures for Multi-Modal Learning
Optimization
Task Relationship Learning
Benchmarks
Benchmarks for Computer Vision
Benchmarks for Natural Language Processing
Benchmarks for Reinforcement Learning
Benchmarks for Multi-Modal Learning
MTL with other paradigms
Theoretical Analysis